
Sinbadflow is a simple pipeline creation and execution tool. It was created having Databricks notebooks workflow in mind, however with flexible implementation options the tool can be extended and customized to fit any task. Named after famous cartoon “Sinbad: Legend of the Seven Seas” the library provides ability to create and run agents with specific triggers and conditional functions in parallel or single mode. With the simple, yet intuitive, fully code based syntax we can create elaborative pipelines to solve any data engineering, data science or software development task.
As this is both my first open source project and first open source project from Data Analytics team at Storebrand, I am excited to present it to you and I hope you will find it useful in your day to day tasks.
Why do we need another pipeline tool?
Fun fact - the project started as a joke. One day I was exploring the possibilities to run multiple Databricks notebooks in parallel and decided to share my findings with our tech lead - Robertas. During our chat he expressed the feeling that he is not keen on using Data Factory in our new data science platform and I made a joke that we should create new pipeline tool by ourselves. Data Factory requires additional setup, virtual machine maintenance and monitoring. Our goal for the new platform was to limit the additional overhead as much as possible. The ultimate solution would be to use one platform and one programming language in it. As most of our work is now done in Databricks it would be convenient to have everything inside it, including notebook pipeline management part. In the official website the suggested solution would use Databricks workflows, however for us this seemed like very crude approach to a problem. Rumors has it the Databricks is working on more elegant pipeline solution, but it’s not available at the time of writing this post.
Why did we decide to create the library from the scratch instead of using already available tools like Airflow, Luigi or Dagster? To sum up the answer in one word - simplicity. Tools like Airflow are very effective with a lot of features and talented contributors behind them. However, we are not planning to run very elaborative pipelines, nor do we need the fancy UI for process creation. it would be hard to do even if we want - we are working strictly inside private network and setting up additional hosting for Airflow would be complicated. For that reason we decided to create our own tool with pure code-based approach and full Databricks notebooks integration. At the end - we are very happy with the result as it satisfies all our current needs.
How does it work?
Sinbadflow at it’s core uses linked list data structure. The pipeline is made of executable elements which are called Agents. A basic visual example is shown in the picture.
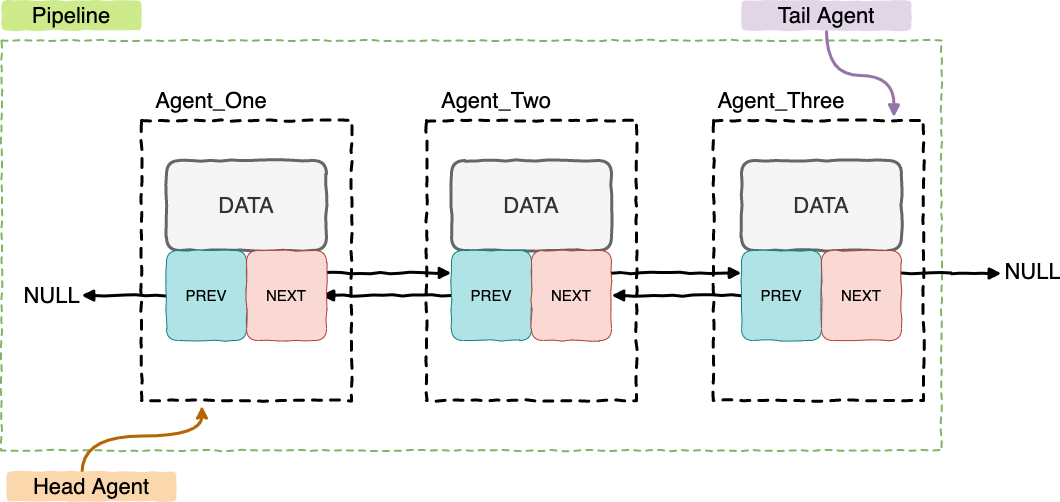
Each of the object has a reference to the previous and next element in the pipeline (except head and tail elements) and the payload (data). In order to execute the pipeline we need to find the head node and execute elements by following the next pointer path until the tail node. In Databricks agent case data holds the location of the notebook which will be executed. All the additional functionality, mentioned later in the blog posts, ties around this basic concept.
How to get started?
To install the library use pip:
pip install sinbadflow
To use it as Databricks notebooks executor we can use the following piece of code:
from sinbadflow.agents.databricks import DatabricksAgent as dbr
from sinbadflow import Sinbadflow
ntb1 = dbr('/notebook1')
ntb2 = dbr('/notebook2')
ntb3 = dbr('/notebook3')
one_by_one_pipeline = ntb1 >> ntb2 >> ntb3
ntb4 = dbr('/notebook4')
ntb5 = dbr('/notebook5')
ntb6 = dbr('/notebook6')
parallel_pipeline = [ntb4, ntb5, ntb6]
summed_pipeline = one_by_one_pipeline >> parallel_pipeline
sf = Sinbadflow()
sf.run(summed_pipeline)
In the example above six DatabricksAgents objects are created. To execute notebooks in one-by-one mode use >> notation between the objects. To run multiple object in parallel, put objects into python list and then use the same >> notation between them. Parallel element will be executed using ThreadPoolExecutor functionality. We can also connect pipelines to one another with the same notation as shown in variable summed_pipeline creation. Visual representation of the pipeline is also supported with print_pipeline method:
sf.print_pipeline(summed_pipeline)
OUT:
'''
↓ -----START-----
↓ Agent(s) to run: ['• name: DatabricksAgent...
...
Triggers
For execution management Trigger functionality is supported which executes elements dependent on previous run/global run status. Supported triggers:
Trigger.DEFAULT- default trigger, the agent is always executed.Trigger.OK_PREV- agent will be executed if previous agent finished successfully.Trigger.OK_ALL- agent will be executed if so far no fails are recorded in the pipeline.Trigger.FAIL_PREV- agent will be executed if previous agent run failed.Trigger.FAIL_ALL- agent will be executed if all previous runs failed.
Triggers can be passed to the agent as trigger parameter. One common usage for triggers would be to have different output handles in parallel block as displayed in the code below. Depending on /execute notebook status one of the handles will be executed.
from sinbadflow import Trigger
execution = dbr('/execute')
handle_ok_fail = [dbr('/handle_fail', Trigger.FAIL_PREV),
dbr('/handle_ok', Trigger.OK_PREV)]
pipeline = execution >> handle_ok_fail
Conditional functions
A more elaborate execution handling can be implemented using conditional function check. A boolean function is passed to the agent and gets evaluated at the same time as trigger.
from datetime import date
def is_monday():
return date.today().weekday() == 0
notebook1 = dbr('/notebook1', conditional_func=is_monday)
notebook2 = dbr('/notebook2', conditional_func=is_monday)
pipeline = notebook1 >> notebook2
In the example above the notebooks will be executed only on Mondays. There is also a functionality to apply the same conditional function to the whole pipeline:
from sinbadflow.utils import apply_conditional_func
pipeline = dbr('/notebook1') >> dbr('/notebook2') >> dbr('/notebook3')
pipeline = apply_conditional_func(pipeline, is_monday)
Custom agents
Sinbadflow was created to be extendable, general purpose pipeline executor. For that reason it provides an ability to create new custom agents, which can be incorporated into pipelines.
In the example below we are creating new DummyAgent which must inherit from BaseAgent and implement run() method.
from sinbadflow.agents import BaseAgent
from sinbadflow import Trigger
from sinbadflow import Sinbadflow
class DummyAgent(BaseAgent):
def __init__(self, data=None, trigger=Trigger.DEFAULT, **kwargs):
super(DummyAgent, self).__init__(data, trigger, **kwargs)
def run(self):
print(f' Running my DummyAgent with data: {self.data}')
secret_data = DummyAgent('secret_data')
parallel_data = [DummyAgent('simple_data', conditional_func=is_monday),
DummyAgent('important_data', Trigger.OK_ALL)]
pipeline = secret_data >> parallel_data
sf = Sinbadflow()
sf.run(pipeline)
Depending on the need, we might extend the list of agents that comes out of the box. For now the only supported agent is DatabricksAgent.
DatabricksAgent
Out of the box Sinbadflow comes with DatabricksAgent which can be used to run Databricks notebooks on interactive or job clusters. DatabricksAgent init arguments:
notebook_path #Notebook location in the workspace
trigger = Trigger.DEFAULT #Trigger
timeout=1800 #Notebook run timeout
args={} #Notebook arguments
cluster_mode='interactive' #Cluster mode (interactive/job)
job_args={) #Job cluster parameters
conditional_func=default_func() #Conditional function
We can also control job cluster parameters with job_args argument. The default parameters are:
{
'spark_version': '6.4.x-scala2.11',
'node_type_id': 'Standard_DS3_v2',
'driver_node_type_id': 'Standard_DS3_v2',
'num_workers': 1
}
You can check here to learn more about job api parameters. By default the notebook will be executed on interactive cluster using dbutils library. To run notebook on separate job cluster use the following code:
from sinbadflow.agents.databricks import DatabricksAgent as dbr, JobSubmitter
from sinbadflow.executor import Sinbadflow
#set new job_args
new_job_args = {
'num_workers':10,
'driver_node_type_id': 'Standard_DS3_v2'
}
job_notebook = dbr('notebook1', job_args=new_job_args, cluster_mode='job')
interactive_notebook = dbr('notebook2')
pipeline = job_notebook >> interactive_notebook
##Access token is used for job cluster creation and notebook submission
JobSubmitter.set_access_token('<DATABRICKS ACCESS TOKEN>')
sf = Sinbadflow()
sf.run(pipeline)
As shown in the example above you can mix and match agent runs on interactive/job clusters to achieve the optimal solution. This can help you to save time and cost in the long run.
Additional information
If you are interested to dig deeper the full code of the project can be found here.
You can also go throught the full API documentation - here
The library is uploaded to PyPI.
All comments, suggestions, changes and pull requests are very welcomed!
Special thank you
Special thank you to our tech lead Robertas Sys for all suggestions, criticism and encouragement to push forward. Also huge thanks to our new team member Emilija Lamanauskaite who lend a helping hand on building Databricks job submission functionality.
